RAG คืออะไร และใช้กับธุรกิจอย่างไร? นี่คือประเด็นที่ผู้นำองค์กร (Executives) และวิศวกรซอฟต์แวร์ (Developers) ทั่วโลกกำลังให้ความสนใจสูงสุด เมื่อ Generative AI กลายเป็นมาตรฐานใหม่ของธุรกิจ คำถามที่ตามมาคือ “เราจะทำให้ AI ตอบคำถามโดยอ้างอิงจากข้อมูลความลับของบริษัทเราได้อย่างไร โดยไม่ให้มันแต่งเรื่องขึ้นมาเอง?” คำตอบของปัญหานี้คือเทคโนโลยีที่เรียกว่า RAG (Retrieval-Augmented Generation)
ในบทความนี้ ผู้เชี่ยวชาญด้าน AI Development จาก Zairosoft จะพาทุกท่านไปเจาะลึกแบบทะลุปรุโปร่ง ตั้งแต่หลักการทำงานของ RAG การออกแบบสถาปัตยกรรม (Architecture) ไปจนถึงการเขียนโค้ดเพื่อสร้าง รับทำ AI Chatbot หรือ รับทำ AI Agent ที่สามารถดึงข้อมูลองค์กรมาใช้งานได้จริง

RAG คืออะไร
RAG เป็นกรอบการทำงาน (Framework) ด้านปัญญาประดิษฐ์ ที่ยกระดับความแม่นยำและความน่าเชื่อถือของโมเดลภาษาขนาดใหญ่ (Large Language Models – LLM) อย่าง OpenAI GPT-4 หรือ Anthropic Claude โดยการ “ดึงข้อมูล (Retrieve)” ที่เกี่ยวข้องจากฐานข้อมูลภายนอก (เช่น เอกสาร PDF ของบริษัท, ฐานข้อมูลลูกค้า) มา “ป้อน (Augment)” ให้กับ AI ก่อนที่จะสั่งให้มัน “สร้างคำตอบ (Generate)”
RAG ย่อมาจากอะไร
คำว่า RAG ย่อมาจาก 3 ขั้นตอนหลักในการทำงาน:
- R – Retrieval (การค้นคืน): เมื่อผู้ใช้ถามคำถาม ระบบจะไปค้นหาข้อมูลที่ “เกี่ยวข้องที่สุด” จากฐานข้อมูลขององค์กร (มักเป็น Vector Database คืออะไร)
- A – Augmented (การเสริมแต่ง): นำข้อมูลที่ค้นหาได้ มาแนบเข้าไปใน Prompt ร่วมกับคำถามเดิมของผู้ใช้ (Context Injection)
- G – Generation (การสร้างผลลัพธ์): ส่ง Prompt ที่มีทั้งคำถามและข้อมูลอ้างอิง ไปให้ LLM เพื่อสังเคราะห์และสร้างคำตอบสุดท้ายที่ถูกต้อง
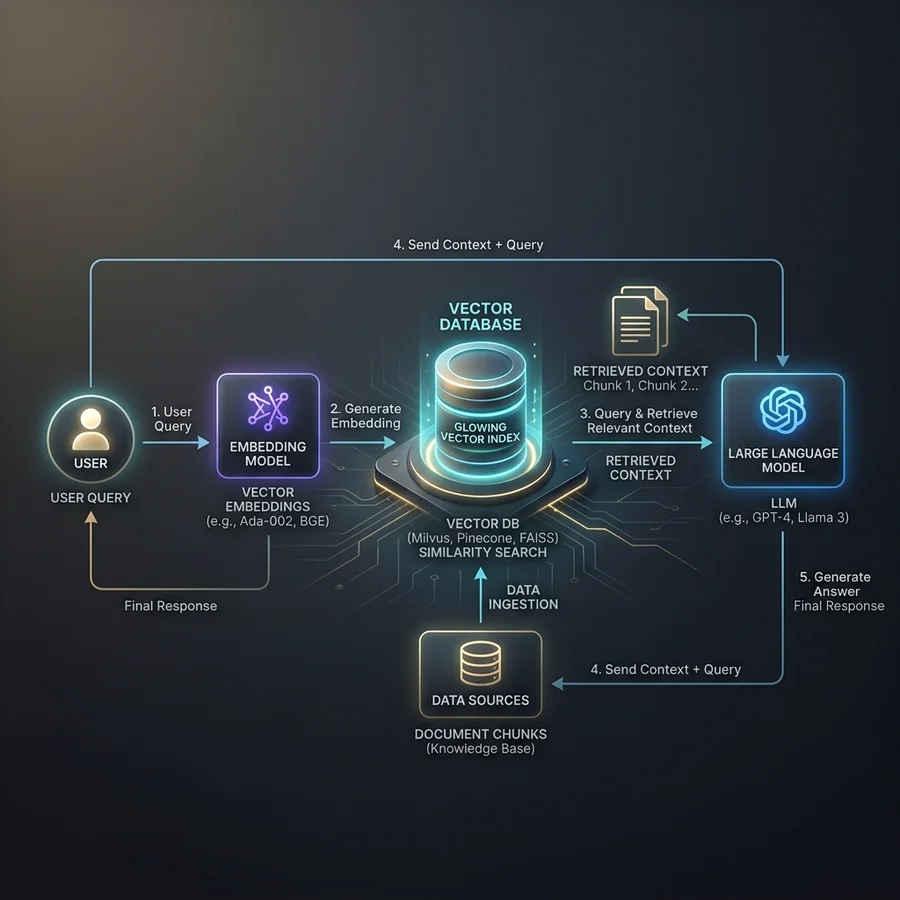
RAG ทำงานอย่างไร (เจาะลึกระดับ Architecture)
เพื่อให้เห็นภาพว่า RAG คืออะไร และใช้กับธุรกิจอย่างไร อย่างแท้จริง เราต้องกางแผนผังสถาปัตยกรรม (Architecture) ดูกระบวนการหลังบ้าน
1. Data Source (แหล่งข้อมูล)
เริ่มต้นจากการนำไฟล์ข้อมูลของธุรกิจ เช่น PDF คู่มือพนักงาน, ข้อมูลสินค้า, ประวัติการตอบแชท หรือข้อมูลจาก Confluence มาทำความสะอาด (Data Cleansing) และตัดแบ่งออกเป็นชิ้นเล็กๆ (Chunking) เพื่อไม่ให้ล้น Context Window ของ AI
2. Embedding
Embedding คืออะไร? มันคือกระบวนการแปลง “ข้อความ” ให้กลายเป็น “ตัวเลข (Vector/Array)” เพื่อให้คอมพิวเตอร์เข้าใจ “ความหมายแฝง (Semantic Meaning)” ของประโยค แทนที่จะเข้าใจแค่ตัวอักษร
3. Vector Database
นำเวกเตอร์ตัวเลขเหล่านั้นไปเก็บไว้ในฐานข้อมูลเฉพาะทาง (เช่น Pinecone หรือ Weaviate) ซึ่งออกแบบมาเพื่อการค้นหาความคล้ายคลึงของเวกเตอร์ (Vector Similarity Search) ด้วยความเร็วแสง
4. Retriever (ผู้ค้นคืน)
เมื่อลูกค้าพิมพ์ถามว่า “บริษัทมีนโยบายลาป่วยกี่วัน?” ระบบจะนำคำถามนี้ไปทำ Embedding เป็นเวกเตอร์ แล้วนำไปวิ่งเทียบใน Vector Database เพื่อดึง 5 ย่อหน้าที่เกี่ยวข้องกับ “นโยบายวันหยุด/ลาป่วย” ออกมา
5. LLM & Response Generation
ระบบจะนำ 5 ย่อหน้าที่ดึงมาได้ แนบไปพร้อมกับคำถาม ส่งให้ LLM (เช่น GPT-4) พร้อมสั่งว่า “จงตอบคำถามผู้ใช้ โดยอิงจากเอกสารอ้างอิงที่แนบมานี้เท่านั้น หากไม่มีในเอกสาร ให้ตอบว่าไม่ทราบ”
RAG แตกต่างจาก AI Chatbot ปกติอย่างไร?
| คุณสมบัติ | AI Chatbot ทั่วไป (เช่น ChatGPT พื้นฐาน) | RAG-based Chatbot |
|---|---|---|
| แหล่งความรู้ (Knowledge) | รู้แค่ข้อมูลที่ถูกเทรนมาในอดีต (Cut-off date) | รู้ข้อมูลความลับล่าสุดของบริษัทแบบ Real-time |
| ความแม่นยำ (Accuracy) | อาจแต่งเรื่องขึ้นมาเองเมื่อไม่รู้คำตอบ | ตอบโดยอิงจากเอกสารอ้างอิง ลดการมั่วข้อมูลได้เกือบ 100% |
| การอัปเดตข้อมูล | ต้องเสียเงิน Fine-tune โมเดลใหม่ทั้งหมด | แค่เพิ่มเอกสารใหม่เข้า Vector Database ก็ใช้งานได้ทันที |
| การอ้างอิง (Citations) | บอกไม่ได้ว่าเอาข้อมูลมาจากหน้าไหน | สามารถแนบลิงก์หน้า PDF อ้างอิงกลับไปให้คนอ่านตรวจสอบได้ |
RAG ช่วยแก้ปัญหา AI Hallucination อย่างไร?
ปัญหาใหญ่ที่สุดที่ธุรกิจไม่กล้านำ AI มาใช้คือ AI Hallucination (อาการหลอน/แต่งเรื่อง) เช่น บอทไปลดราคาสินค้าให้ลูกค้าเองโดยพลการ หรือให้ข้อมูลทางการแพทย์ที่ผิดพลาด
RAG แก้ปัญหานี้อย่างตรงจุด ด้วยการทำ Context Injection (การฉีดบริบท) บังคับให้ LLM กลายสภาพเป็นเพียง “นักสรุปความ” แทนที่จะเป็น “ผู้รอบรู้” โดยเราจะล็อก System Prompt อย่างแน่นหนาว่า ห้ามตอบเกินกว่าข้อมูลที่ Retrieval ดึงมาให้เด็ดขาด
ทำไมธุรกิจยุคใหม่เริ่มใช้ RAG?
คำถามที่ว่า RAG คืออะไร และใช้กับธุรกิจอย่างไร ได้รับการพิสูจน์แล้วจากองค์กรชั้นนำ ธุรกิจหันมาใช้ RAG เพราะความ คุ้มค่า (Cost-effective) การนำโมเดล AI ระดับโลกอย่าง Llama 3 หรือ GPT-4 มาทำ Fine-tuning เพื่อสอนข้อมูลบริษัท ต้องใช้ Data Scientist, การเตรียมข้อมูลนับหมื่นบรรทัด, และค่าประมวลผลมหาศาล แถมข้อมูลยังเก่าทันทีที่เทรนเสร็จ ในขณะที่ระบบ RAG ใช้เวลาพัฒนาสั้นกว่ามาก และค่าใช้จ่ายถูกกว่าหลายเท่า
RAG ใช้กับธุรกิจอะไรได้บ้าง (Use Cases)
1. Customer Support & Call Center
ลดภาระทีม Support ลง 60% โดยให้ RAG Bot เข้าถึงประวัติการซ่อม หรือคู่มือผลิตภัณฑ์ หากลูกค้าถามวิธีแก้ Error Code ระบบจะดึงคู่มือหน้าที่ถูกต้องมาสรุปให้ทันที
2. Internal Company AI (HR / IT Helpdesk)
พนักงานใหม่สามารถทักแชทถามเรื่อง นโยบายการเบิกจ่ายสวัสดิการ, ขั้นตอนการขอเบิกอุปกรณ์ไอที หรือวิธีตั้งค่า VPN แทนที่จะต้องไปไล่อ่าน Wiki องค์กรยาวๆ
3. Document Search & Legal Research
สำหรับสำนักงานกฎหมาย ทนายสามารถถาม RAG ที่เชื่อมต่อกับคำพิพากษาศาลนับแสนฉบับ เพื่อหา “คดีตัวอย่างในปี 2565 ที่เกี่ยวกับการละเมิดลิขสิทธิ์ซอฟต์แวร์” ระบบจะดึงคดีที่เกี่ยวข้องมาสรุปพร้อมเลขคดีอ้างอิง
Vector Database คืออะไร และสำคัญอย่างไรกับ RAG
หัวใจที่ทำให้ RAG ค้นหาข้อมูลได้เก่งไม่ใช่ SQL Database แบบเดิม แต่คือ Vector Database ที่เปลี่ยนโลกการค้นหาจาก Keyword-based ไปสู่ Semantic Search (การค้นหาด้วยความหมาย) นี่คือตัวท็อปในตลาดที่ Developer มักเลือกใช้:
- Pinecone: บริการระดับ Enterprise แบบ Fully Managed ใช้งานง่าย เสถียรสูง เหมาะกับองค์กรที่ไม่ต้องการดูแล Server เอง
- Weaviate / Qdrant: รองรับการค้นหาแบบ Hybrid Search (Vector + Keyword) สามารถ Deploy แบบ On-premise ได้
- ChromaDB: ได้รับความนิยมสูงมากในหมู่นักพัฒนาที่สร้าง รับทำ AI Automation โปรเจกต์ขนาดเล็กถึงปานกลาง ทำงานแบบ Local ได้ลื่นไหล
RAG กับ AI Agent ต่างกันอย่างไร?
หากคุณเคยอ่านบทความ AI Agent คืออะไรในมุม Developer คุณอาจสงสัยว่ามันเหมือนกันไหม? ความจริงคือ RAG เป็นเพียง “เครื่องมือ (Tool) หรือทักษะหนึ่ง” ที่ AI Agent หยิบมาใช้
RAG มีหน้าที่หลักคือ “ค้นหาข้อมูลมาตอบ” (Read-only) แต่ AI Agent สามารถทำได้ทั้งการใช้ RAG เพื่ออ่านความรู้ และยังสามารถ “ลงมือทำ” (Action/Write) เช่น ส่งอีเมล สร้างบิล หรือรันโค้ด ผ่าน Tool Calling ได้
LangChain และ LangGraph ใช้กับ RAG อย่างไร
LangChain คือ Framework ที่เกิดมาเพื่อทำ RAG โดยเฉพาะ มันมีโมดูลในการทำ Document Loading (อ่าน PDF, Word), Text Splitting (การหั่นข้อความ), และการต่อท่อ Retriever Pipeline อย่างสำเร็จรูป ในขณะที่ LangGraph ถูกนำมาใช้ทำ Advanced RAG (เช่น Self-Reflective RAG) ที่บังคับให้ AI ประเมินคำตอบของตัวเองซ้ำๆ ว่าข้อมูลที่ดึงมาตรงคำถามหรือไม่ หากไม่ตรงให้กลับไปดึงใหม่
ตัวอย่าง Code: การทำงานของ RAG Pipeline ด้วย Python
เพื่อให้คนสายเทคนิคเห็นภาพว่า RAG คืออะไร และใช้กับธุรกิจอย่างไร นี่คือตัวอย่างโครงสร้างโค้ดการทำ RAG แบบพื้นฐาน:
import os
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# 1. Initialize LLM & Embeddings Model
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
embeddings = OpenAIEmbeddings()
# 2. Connect to existing Vector Database (ChromaDB)
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # Retrieve top 3 chunks
# 3. Create RAG System Prompt
system_prompt = (
"คุณคือผู้ช่วย AI ของบริษัท Zairosoft ตอบคำถามลูกค้าโดยอ้างอิงจากข้อมูลต่อไปนี้เท่านั้นn"
"หากไม่มีข้อมูลที่เกี่ยวข้อง ให้ตอบอย่างสุภาพว่า 'ไม่ทราบข้อมูล' ห้ามคาดเดาเองเด็ดขาดnn"
"{context}"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
])
# 4. Create the Chain & Execute
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
response = rag_chain.invoke({"input": "บริษัทรับทำ Web Application ด้วยภาษาอะไรบ้าง?"})
print(response["answer"])ปัญหาที่ Developer มักเจอเวลาใช้ RAG
การเขียนโค้ดทำ RAG แบบพื้นฐาน (Naive RAG) ใช้เวลาเพียงไม่กี่ชั่วโมง แต่การนำไปใช้จริงในองค์กรระดับ Enterprise มักจะเจอปัญหาเหล่านี้:
1. Chunking Problem (ปัญหาการหั่นคำ)
หากหั่นย่อหน้าผิดที่ ความหมายจะเปลี่ยนทันที การทำ Semantic Chunking ที่ดีต้องอาศัยการเข้าใจภาษาและโครงสร้างเอกสาร (เช่น PDF ที่มีตารางซ้อนกัน)
2. Bad Retrieval
ดึงข้อมูลมาได้ แต่ไม่ใช่ข้อมูลที่ผู้ใช้ต้องการ (Low Relevance) ปัจจุบันต้องแก้ด้วยการทำ Hybrid Search (ค้นหาความหมาย + ค้นหาคีย์เวิร์ด) และใช้ Re-ranking Model จัดเรียงลำดับความสำคัญของเอกสารใหม่ก่อนส่งให้ LLM
3. Cost Optimization
การดึงข้อมูล 10 หน้ากระดาษส่งให้ LLM อ่านทุกครั้งที่ลูกค้าพิมพ์ถาม จะทำให้ค่า API (Token Cost) พุ่งทะยาน Developer ต้องรู้เทคนิคการทำ Prompt Caching หรือลดขนาด Context
Checklist ก่อนเริ่มทำระบบ RAG สำหรับองค์กร
- ✅ ข้อมูลบริษัทที่กระจัดกระจาย (Silo) ถูกรวบรวมและจัดหมวดหมู่แล้วหรือยัง?
- ✅ ข้อมูลมีความลับทางการค้าหรือไม่? (หากมี ต้องพิจารณาใช้ LLM แบบ On-premise แทน API)
- ✅ มีการจัดการสิทธิ์การเข้าถึงข้อมูล (Data Access Control) หรือไม่? ไม่ใช่ให้พนักงานทั่วไปถาม RAG แล้วดึงเงินเดือน CEO ออกมาได้
Zairosoft ช่วยธุรกิจของคุณวางระบบ RAG อย่างไร
ที่ Zairosoft เราไม่ได้นำ Framework สำเร็จรูปมาครอบใช้งานแบบง่ายๆ ทีม Software Architect ของเราเชี่ยวชาญการทำ Advanced RAG Pipelines ระดับโปรดักชัน เราออกแบบตั้งแต่ Data Ingestion Pipeline, การทำ Hybrid Search, ตลอดจนการทำ Information Security (RBAC) เพื่อให้มั่นใจว่า AI ขององค์กรคุณจะฉลาด แม่นยำ และปลอดภัยสูงสุด
สรุป: RAG คืออะไร และใช้กับธุรกิจอย่างไร?
สรุปให้เข้าใจง่ายที่สุด RAG คือสะพานเชื่อมระหว่าง “ความฉลาดของ AI” กับ “ข้อมูลความลับขององค์กร” มันช่วยขจัดปัญหา AI หลอนข้อมูล และทำให้ธุรกิจสามารถมี “พนักงานดิจิทัล” ที่เชี่ยวชาญผลิตภัณฑ์ของบริษัทอย่างทะลุปรุโปร่ง ช่วยตอบคำถามลูกค้า ลดงานแอดมิน และเพิ่มประสิทธิภาพการทำงานได้อย่างมหาศาล
หากคุณพร้อมที่จะยกระดับองค์กรด้วยระบบ AI ที่ตอบคำถามจากข้อมูลบริษัทได้จริง ติดต่อทีมผู้เชี่ยวชาญของ Zairosoft วันนี้ เพื่อรับคำปรึกษาในการออกแบบระบบที่เหมาะสมกับธุรกิจคุณที่สุดครับ!
FAQ (คำถามที่พบบ่อย)
- RAG คืออะไร?
กระบวนการดึงข้อมูลจากเอกสารบริษัทมาป้อนให้ AI อ่านก่อนที่จะให้ AI สังเคราะห์เป็นคำตอบ เพื่อให้ได้คำตอบที่แม่นยำและไม่อ้างอิงข้อมูลมั่ว - RAG ต่างจาก AI Chatbot ทั่วไปอย่างไร?
AI Chatbot ปกติจะตอบคำถามจากข้อมูลที่ถูกสอนมาในอดีต (ซึ่งอาจจะเก่าและไม่มีข้อมูลบริษัทคุณ) แต่ RAG จะค้นหาข้อมูลล่าสุดของบริษัทคุณมาตอบเสมอ - RAG ต้องใช้ Vector Database หรือไม่?
จำเป็นมากครับ เพราะ Vector Database ออกแบบมาให้ค้นหาข้อมูลด้วย “ความหมาย (Semantic)” ทำให้ค้นหาเจอแม้ผู้ใช้จะสะกดคำผิดหรือใช้คำพ้องความหมาย - RAG ใช้กับ LINE OA ได้ไหม?
ได้แน่นอน 100% ครับ เราสามารถต่อ API นำระบบ RAG ไปเป็นสมองให้แชทบอทใน LINE OA หรือ Facebook Messenger ได้เลย - RAG ต้อง Fine-tune โมเดลหรือไม่?
ไม่ต้องครับ นี่คือข้อดีของ RAG คุณไม่จำเป็นต้องสอนโมเดลใหม่ให้เสียเงิน เพียงแค่อัปเดตไฟล์ในฐานข้อมูล ระบบ AI ก็จะรับรู้ข้อมูลใหม่ทันที - RAG ใช้กับเอกสาร PDF ได้ไหม?
รองรับทั้ง PDF, Word, Excel, CSV และการดึงข้อมูลจากเว็บไซต์องค์กรครับ