Sitemap และ Robots.txt สำคัญอย่างไร
Sitemap และ Robots.txt สำคัญอย่างไร เป็นคำถามที่เจ้าของเว็บไซต์, SEO Specialist และ Developer ควรเข้าใจตั้งแต่ช่วงวางโครงสร้างเว็บ ไม่ใช่รอให้เว็บมีปัญหา Index ไม่ครบแล้วค่อยแก้ เพราะสองไฟล์นี้เกี่ยวข้องโดยตรงกับวิธีที่ Googlebot เข้ามาอ่านเว็บไซต์ ค้นพบ URL ใหม่ แยกแยะหน้าที่ควรให้ความสำคัญ และหลีกเลี่ยงพื้นที่ที่ไม่ควรถูก Crawl
ในงาน Technical SEO จริง ปัญหาใหญ่จำนวนมากไม่ได้เกิดจากคอนเทนต์ไม่ดีเสมอไป แต่เกิดจาก “Google เข้าเว็บไม่ถูกทาง” เช่น Sitemap ส่ง URL ที่ไม่ควร Index, Robots.txt บล็อกไฟล์สำคัญ, หน้า canonical ผิด, URL duplicate ถูกส่งซ้ำจำนวนมาก หรือเว็บขนาดใหญ่ปล่อยให้ crawler เสียเวลาไปกับ filter, search result และ parameter URL จน Crawl Budget ถูกใช้ผิดที่
คำตอบสั้น ๆ: Sitemap คือแผนที่ที่ช่วยบอก Search Engine ว่า URL สำคัญของเว็บไซต์อยู่ที่ไหน ส่วน Robots.txt คือไฟล์กฎที่บอก crawler ว่าส่วนใดของเว็บควรหรือไม่ควรถูก Crawl เมื่อใช้ร่วมกันอย่างถูกต้อง จะช่วยให้ Google ค้นพบหน้าเว็บดีขึ้น จัดการ Crawling ได้มีประสิทธิภาพขึ้น ลดปัญหา Index ผิดหน้า และสร้างฐาน Technical SEO ที่แข็งแรงในระยะยาว

Featured Snippet: Sitemap และ Robots.txt สำคัญอย่างไร
Sitemap และ Robots.txt สำคัญอย่างไร ต่อ SEO? Sitemap ช่วยให้ Google ค้นพบ URL สำคัญและเข้าใจโครงสร้างเว็บไซต์ ส่วน Robots.txt ช่วยควบคุมการ Crawl ของ bot ในพื้นที่ที่ไม่ต้องการให้ถูกอ่าน ทั้งสองไฟล์ไม่ใช่ตัวเร่งอันดับโดยตรง แต่เป็นพื้นฐาน Technical SEO ที่ช่วยให้ Crawling, Indexing และ Crawl Budget ทำงานมีประสิทธิภาพขึ้น
Sitemap คืออะไร
Sitemap คือไฟล์หรือหน้าเว็บที่รวบรวม URL สำคัญของเว็บไซต์ เพื่อช่วยให้ Search Engine และผู้ใช้ค้นพบโครงสร้างเนื้อหาได้ง่ายขึ้น โดยในมุม SEO คำว่า Sitemap มักหมายถึง XML Sitemap ซึ่งสร้างขึ้นให้ crawler อ่านเป็นหลัก
XML Sitemap ไม่ได้บังคับให้ Google ต้อง Index ทุก URL ที่อยู่ในไฟล์ แต่เป็นสัญญาณบอกว่า “นี่คือ URL ที่เจ้าของเว็บเห็นว่าสำคัญและควรให้ crawler พิจารณา” Google จะนำข้อมูลนี้ไปใช้ร่วมกับปัจจัยอื่น เช่น internal links, canonical tag, noindex, คุณภาพเนื้อหา, สถานะ HTTP และความสอดคล้องของ URL
เว็บไซต์ขนาดเล็กที่มีโครงสร้าง internal link ดีอาจถูกค้นพบได้โดยไม่ต้องพึ่ง Sitemap มากนัก แต่สำหรับเว็บไซต์ธุรกิจยุคใหม่ที่มีหลายประเภทเนื้อหา เช่น บทความ, landing page, service page, product page, category, media, multilingual page หรือ dynamic URL, Sitemap ยังเป็นเครื่องมือสำคัญที่ช่วยให้ระบบค้นหาทำงานชัดเจนขึ้น
หน้าที่หลักของ Sitemap
- ช่วยบอก URL ที่ต้องการให้ Search Engine รู้จัก
- ช่วยให้หน้าใหม่ถูกค้นพบเร็วขึ้น โดยเฉพาะหน้าที่ internal link ยังไม่แข็งแรง
- ช่วยจัดกลุ่ม URL ตามประเภท เช่น post, page, product, category
- ช่วยตรวจสอบสถานะ Index ผ่าน Google Search Console ได้ง่ายขึ้น
- ช่วยทีม SEO และ Developer เห็นโครงสร้าง URL ที่ระบบส่งออกจริง
Robots.txt คืออะไร
Robots.txt คือไฟล์ข้อความธรรมดาที่อยู่บริเวณ root ของเว็บไซต์ เช่น https://example.com/robots.txt มีหน้าที่บอก crawler ว่า URL path ใดควรถูก Crawl หรือไม่ควรถูก Crawl โดยใช้กฎ เช่น User-agent, Allow, Disallow และ Sitemap
สิ่งที่ต้องเข้าใจให้ชัดคือ Robots.txt ใช้ควบคุมการ Crawl ไม่ใช่เครื่องมือสั่ง Noindex โดยตรง หาก URL ถูก block ด้วย Robots.txt แต่มี external link ชี้เข้ามา Google อาจยังรู้จัก URL นั้นและแสดงเป็นผลลัพธ์แบบไม่มี snippet ได้ในบางกรณี เพราะ Google ไม่สามารถเข้าไปอ่านเนื้อหาหรือ meta noindex ในหน้านั้นได้
ในเชิง Developer, Robots.txt เป็นไฟล์เล็กมากแต่ impact ใหญ่มาก การพิมพ์ผิดเพียงบรรทัดเดียวสามารถทำให้ Googlebot ไม่เข้าเว็บทั้งเว็บ, ไม่โหลด CSS/JS, ไม่เห็น rendered content หรือเสียเวลา crawl path ที่ไม่ควรเปิดให้ bot เข้าอ่าน
หน้าที่หลักของ Robots.txt
- ควบคุมพื้นที่ที่ crawler สามารถเข้าถึงได้
- ลดการ Crawl ใน path ที่ไม่มีคุณค่าต่อ SEO เช่น internal search, cart, checkout, admin
- ช่วยจัดการ Crawl Budget สำหรับเว็บขนาดใหญ่
- ระบุ URL ของ Sitemap ให้ crawler ค้นพบง่ายขึ้น
- ลด server load จาก bot ในบางประเภทของเว็บไซต์
Sitemap และ Robots.txt ต่างกันอย่างไร
แม้ทั้งสองไฟล์เกี่ยวกับ Search Engine เหมือนกัน แต่หน้าที่ต่างกันชัดเจน Sitemap คือรายการ URL ที่อยากให้ค้นพบ ส่วน Robots.txt คือกฎควบคุมการเข้าถึงของ crawler ความเข้าใจผิดที่พบบ่อยคือคิดว่า “ใส่ URL ใน Sitemap แล้ว Google ต้อง Index” หรือ “ใส่ Disallow แล้วหน้านั้นจะไม่ติด Google แน่นอน” ซึ่งทั้งสองข้อไม่ถูกต้องทั้งหมด
| หัวข้อ | Sitemap | Robots.txt |
|---|---|---|
| หน้าที่หลัก | บอก URL สำคัญให้ Search Engine ค้นพบ | ควบคุมว่า crawler ควรหรือไม่ควร Crawl path ใด |
| รูปแบบไฟล์ | ส่วนใหญ่เป็น XML | TXT ธรรมดา |
| เกี่ยวกับ Crawling | ช่วยเสนอ URL ให้ Crawl | อนุญาตหรือห้าม Crawl บาง path |
| เกี่ยวกับ Indexing | ช่วยให้ Google ค้นพบ URL แต่ไม่รับประกัน Index | ไม่ได้สั่ง Noindex โดยตรง |
| ความเสี่ยงเมื่อผิดพลาด | ส่ง URL ขยะ, duplicate, noindex หรือ redirect จำนวนมาก | บล็อกทั้งเว็บ, บล็อก CSS/JS, บล็อกหน้าสำคัญ |
Sitemap และ Robots.txt สำคัญอย่างไรกับ SEO
Sitemap และ Robots.txt สำคัญอย่างไร ในมุม SEO ต้องมองผ่านสามกระบวนการหลักคือ Crawling, Indexing และ Ranking สองไฟล์นี้ไม่ได้ทำให้เว็บขึ้นอันดับหนึ่งทันที แต่ช่วยให้ Search Engine เข้าถึงและตีความเว็บไซต์ได้ถูกต้อง ซึ่งเป็นเงื่อนไขพื้นฐานก่อนที่เนื้อหาจะมีโอกาสแข่งขันในผลการค้นหา
ช่วยให้ Google Crawl เว็บได้ง่ายขึ้น
Googlebot ค้นพบ URL ผ่านหลายทาง เช่น internal links, external links, Sitemap และ URL ที่เคยรู้จักอยู่แล้ว Sitemap ช่วยเพิ่มความชัดเจนว่า URL ใดควรถูกค้นพบ ส่วน Robots.txt ช่วยลดพื้นที่ที่ไม่จำเป็นต้อง Crawl เช่น path ระบบหลังบ้านหรือ URL ที่สร้างจาก filter จำนวนมาก
ช่วย Index หน้าใหม่เร็วขึ้น
เมื่อมีบทความใหม่ หน้า landing page ใหม่ หรือ product page ใหม่ การอยู่ใน Sitemap ที่ถูกต้องช่วยให้ Google รู้ว่าหน้านั้นมีอยู่จริง แต่การ Index ยังขึ้นกับคุณภาพหน้า, internal links, canonical, robots meta, HTTP status และความซ้ำของเนื้อหา ถ้าหน้าอยู่ใน Sitemap แต่เป็น noindex หรือ canonical ไปหน้าอื่น Google Search Console มักแสดงสถานะที่ทำให้ทีม SEO ต้องตรวจต่อ
ช่วยเว็บไซต์ขนาดใหญ่
เว็บขนาดใหญ่ เช่น E-commerce, Marketplace, News, Directory, Real Estate, Job Board หรือเว็บไซต์องค์กรที่มีหลายภาษา มักมี URL จำนวนมาก Sitemap ช่วยแบ่งประเภท URL และทำให้ทีมตรวจสอบ Coverage ได้ง่ายขึ้น เช่น sitemap-post.xml, sitemap-product.xml, sitemap-category.xml หรือ sitemap-news.xml
ช่วยจัดการ Crawl Budget
Crawl Budget คือทรัพยากรที่ Search Engine ใช้ในการ Crawl เว็บไซต์หนึ่ง ๆ ภายในช่วงเวลา หากเว็บมี URL ขยะจำนวนมาก เช่น parameter, search result, filter combination หรือ archive page ซ้ำ ๆ Googlebot อาจเสียเวลาที่ไม่จำเป็น Robots.txt และโครงสร้าง Sitemap ที่สะอาดจึงช่วยให้ crawler ใช้เวลามากขึ้นกับหน้าที่มีคุณค่าทางธุรกิจ
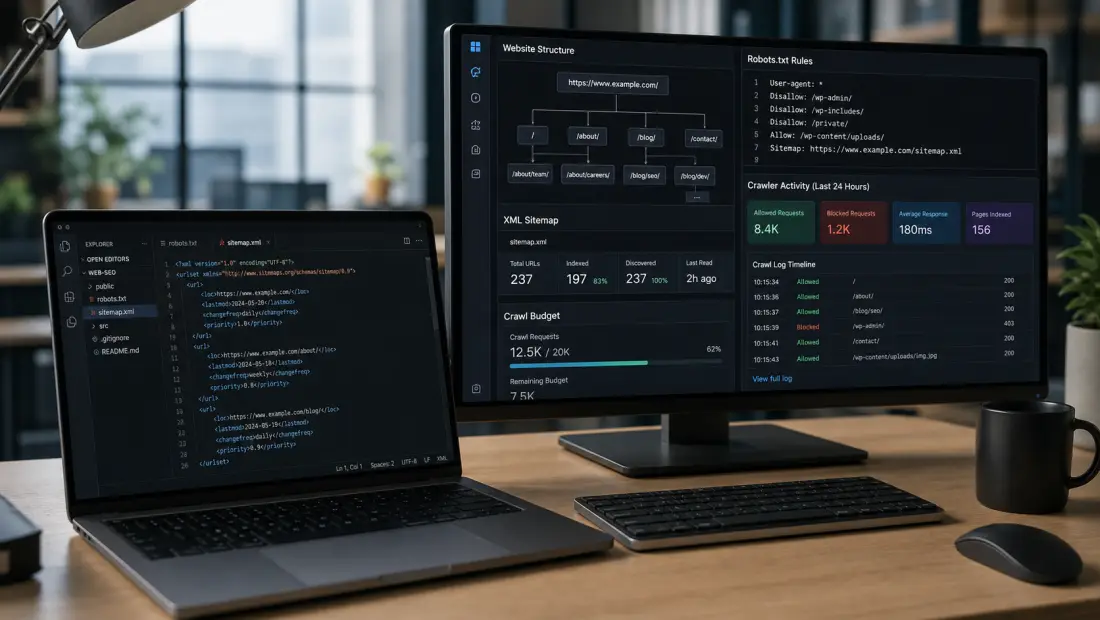
Google ใช้ Sitemap และ Robots.txt อย่างไร
Google ใช้ Sitemap เป็น discovery signal ไม่ใช่คำสั่งบังคับ Index เมื่อ Submit Sitemap ผ่าน Google Search Console ระบบจะอ่าน URL ในไฟล์ ตรวจว่าเข้าถึงได้หรือไม่ แล้วนำไปประมวลผลร่วมกับสัญญาณอื่น หาก URL มีคุณภาพดี โหลดได้เร็ว มี internal link รองรับ และไม่ขัดกับ canonical/noindex โอกาสถูก Index ก็จะสูงขึ้น
เมื่อ Googlebot เข้าสู่เว็บไซต์ โดยทั่วไปจะตรวจ Robots.txt ก่อนเพื่อดูว่ามีกฎอะไรสำหรับ user-agent ของตนเอง จากนั้นจึงตัดสินใจว่าจะ Crawl path ใดได้บ้าง กฎที่เฉพาะเจาะจงกว่าจะมีผลมากกว่ากฎทั่วไป และการใช้ wildcard หรือ pattern ผิดสามารถทำให้ผลลัพธ์ต่างจากที่ทีมคาดไว้
แหล่งอ้างอิงหลักควรเป็น Google Robots.txt Documentation และ Google Sitemap Documentation ไม่ใช่ copy ตัวอย่างจากอินเทอร์เน็ตมาใช้โดยไม่ตรวจบริบทของเว็บ
XML Sitemap คืออะไร
XML Sitemap คือ Sitemap ที่ใช้โครงสร้าง XML ให้ Search Engine อ่าน โดยมี tag เช่น <urlset>, <url>, <loc>, <lastmod>, <changefreq> และ <priority> ในทางปฏิบัติ Google ให้ความสำคัญกับ <loc> และ <lastmod> ที่ถูกต้องมากกว่า tag ที่ถูกใส่แบบเดาสุ่ม
ข้อผิดพลาดที่พบบ่อยคือ CMS หรือ Plugin สร้าง lastmod ใหม่ทุกครั้งแม้เนื้อหาไม่ได้เปลี่ยนจริง ทำให้สัญญาณความสดของหน้าไม่น่าเชื่อถือ ทีม Developer ควรทำให้ lastmod สะท้อนเวลาที่เนื้อหาหลักเปลี่ยนจริง ไม่ใช่เวลาที่ระบบ rebuild หรือ clear cache
HTML Sitemap คืออะไร
HTML Sitemap คือหน้าเว็บสำหรับผู้ใช้จริง มักแสดงรายการลิงก์ไปยังหน้าสำคัญของเว็บไซต์ เหมาะกับเว็บที่มีโครงสร้างใหญ่หรือมีหน้า service หลายกลุ่ม แม้ HTML Sitemap ไม่ใช่สิ่งจำเป็นสำหรับทุกเว็บ แต่สามารถช่วย UX และ internal linking ได้ โดยเฉพาะถ้าออกแบบให้เป็น hub page ที่มีคุณค่าจริง ไม่ใช่แค่รายการลิงก์ยาว ๆ ที่ไม่มีบริบท
Crawl Budget คืออะไร
Crawl Budget คือแนวคิดที่อธิบายว่าระบบค้นหามีทรัพยากรจำกัดในการ Crawl เว็บไซต์หนึ่ง ๆ โดยเฉพาะเว็บไซต์ขนาดใหญ่ สำหรับเว็บเล็ก Crawl Budget อาจไม่ใช่ปัญหาหลัก แต่สำหรับเว็บที่มี URL หลักแสนหรือหลักล้าน การปล่อย URL ที่ไม่มีคุณภาพจำนวนมากให้ bot เข้าอ่าน อาจทำให้หน้าสำคัญถูกค้นพบช้าหรือถูก recrawl น้อยลง
การจัดการ Crawl Budget ไม่ได้แปลว่าต้องบล็อกทุกอย่างด้วย Robots.txt แต่ต้องออกแบบ URL architecture ให้สะอาด ใช้ canonical ให้ถูก ไม่ส่ง URL ที่ไม่มีคุณค่าเข้า Sitemap และใช้ Robots.txt บล็อก path ที่ไม่ควรให้ crawler เสียเวลา เช่น internal search result, parameter ที่สร้าง infinite URL หรือระบบหลังบ้าน
เว็บไซต์ธุรกิจบริการ
เว็บไซต์บริษัทที่มีหน้า service, case study, blog และ landing page ควรใช้ Sitemap เพื่อให้ Google ค้นพบหน้าธุรกิจหลักทั้งหมด และใช้ Robots.txt กัน path ที่ไม่เกี่ยวกับ SEO เช่น login, search หรือระบบ preview
E-commerce และ Product Catalog
ร้านค้าออนไลน์มักมี URL จาก filter, sort, cart, checkout และ account จำนวนมาก Sitemap ควรมีเฉพาะสินค้าและ category ที่ต้องการ Index ส่วน Robots.txt และ canonical ควรช่วยลด URL ขยะ
เว็บองค์กรและเว็บหลายภาษา
เว็บองค์กรที่มีหลายภาษาและหลายแผนกควรแยก Sitemap ตามประเภทเนื้อหา และตรวจ hreflang, canonical, noindex และ robots rules ให้สอดคล้องกันก่อน submit ไป Google Search Console
ตัวอย่าง Sitemap ที่ดี
Sitemap ที่ดีควรมีเฉพาะ URL ที่ต้องการให้ Search Engine พิจารณา Index เป็น canonical URL และตอบสถานะ 200 ตัวอย่าง XML Sitemap พื้นฐาน:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://example.com/</loc>
<lastmod>2026-05-20</lastmod>
</url>
<url>
<loc>https://example.com/technical-seo/</loc>
<lastmod>2026-05-18</lastmod>
</url>
</urlset>ตัวอย่าง Robots.txt ที่ดี
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /?s=
Disallow: /search/
Disallow: /cart/
Disallow: /checkout/
Sitemap: https://example.com/sitemap_index.xmlตัวอย่าง Robots.txt ที่ผิดพลาด
User-agent: *
Disallow: /Block ทั้งเว็บไซต์
Disallow: / เป็นกฎที่อันตรายมากบน production website เพราะหมายถึงไม่อนุญาตให้ crawler เข้า path ใดเลย มักเกิดจากการย้ายเว็บจาก staging ขึ้น live แล้วลืมแก้ Robots.txt
Block CSS / JS
ถ้าบล็อก /wp-content/ หรือ asset folder กว้างเกินไป Google อาจ render หน้าเว็บได้ไม่ครบ ส่งผลต่อการเข้าใจ layout, mobile usability และ content ที่โหลดผ่าน JavaScript
User-agent: *
Disallow: /wp-content/
Disallow: /assets/Crawl Rule Example
User-agent: Googlebot
Disallow: /internal-search/
Disallow: /*?filter=
Allow: /products/
User-agent: *
Disallow: /admin/
Disallow: /tmp/วิธีสร้าง Sitemap สำหรับ WordPress
WordPress รุ่นใหม่มี XML Sitemap พื้นฐานใน core ผ่าน path เช่น /wp-sitemap.xml แต่เว็บไซต์ธุรกิจส่วนใหญ่มักใช้ SEO Plugin เช่น Rank Math หรือ Yoast SEO เพราะควบคุม post type, taxonomy, noindex และ sitemap index ได้ละเอียดกว่า
สำหรับ WordPress ที่ใช้ Rank Math โดยทั่วไป Sitemap มักอยู่ที่:
https://example.com/sitemap_index.xmlวิธีสร้าง Robots.txt สำหรับ WordPress
WordPress สามารถสร้าง virtual Robots.txt ได้ แต่ในโปรเจกต์จริงควรตรวจว่าหน้า /robots.txt แสดงผลกฎที่ต้องการจริงหรือไม่ หากมีไฟล์จริงใน root server ไฟล์นั้นอาจ override ระบบ virtual ของ WordPress หรือ plugin ได้
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-login.php
Disallow: /?s=
Sitemap: https://example.com/sitemap_index.xmlRank Math กับ Sitemap ทำงานอย่างไร
Rank Math ช่วยสร้าง sitemap index แยกตาม content type เช่น post, page, category หรือ product และให้ตั้งค่าว่า post type ใดควรอยู่ใน Sitemap หากหน้าใดตั้ง noindex ผ่าน Rank Math โดยทั่วไปไม่ควรถูกส่งเข้า Sitemap เพราะเป็นสัญญาณขัดกันระหว่าง “ไม่ต้องการ Index” กับ “ส่ง URL ให้ Search Engine พิจารณา”
WordPress Sitemap Example
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://example.com/post-sitemap.xml</loc>
<lastmod>2026-05-20T10:30:00+00:00</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/page-sitemap.xml</loc>
<lastmod>2026-05-18T08:10:00+00:00</lastmod>
</sitemap>
</sitemapindex>Google Search Console เช็ค Sitemap อย่างไร
หลังจากสร้าง Sitemap แล้ว ควร submit ผ่าน Google Search Console ในเมนู Sitemaps จากนั้นตรวจสถานะว่า Google อ่านไฟล์ได้หรือไม่ จำนวน URL ที่ค้นพบกี่รายการ และมี error หรือ warning อะไรหรือไม่
ในงานจริง อย่าดูแค่สถานะ “Success” เพราะ Success หมายถึง Google อ่านไฟล์ได้ ไม่ได้แปลว่าทุก URL ถูก Index แล้ว ควรตรวจต่อใน Page Indexing Report, URL Inspection Tool, Crawl Stats และ log server หากเป็นเว็บขนาดใหญ่
ตัวอย่างการตรวจด้วย Bash
curl -I https://example.com/sitemap_index.xml
curl -I https://example.com/robots.txtตัวอย่างโครงสร้างข้อมูลสำหรับ Audit
{
"url": "https://example.com/technical-seo/",
"in_sitemap": true,
"status_code": 200,
"indexable": true,
"canonical": "https://example.com/technical-seo/",
"blocked_by_robots": false,
"lastmod_is_reliable": true
}ปัญหาที่เว็บไซต์มักเจอเกี่ยวกับ Sitemap และ Robots.txt
Index ไม่ครบ
ถ้า Index ไม่ครบ อย่าเริ่มจากการ submit Sitemap ซ้ำทันที ให้ตรวจว่า URL นั้น indexable จริงหรือไม่ มี internal link หรือเปล่า ถูก canonical ไปหน้าอื่นไหม เนื้อหาบางเกินไปหรือซ้ำกับหน้าอื่นหรือไม่ และถูก block ด้วย Robots.txt หรือไม่
Crawl Error
Crawl Error อาจเกิดจาก server 5xx, DNS, redirect chain, timeout, blocked resource หรือ Sitemap ส่ง URL ที่ไม่มีอยู่จริง การแก้ที่ถูกต้องคือแยกปัญหาเป็นระดับ server, CMS, plugin, routing และ content lifecycle
หน้าไม่ติด Google
หน้าไม่ติด Google ไม่ได้แปลว่า Sitemap เสียเสมอไป อาจเกิดจากคุณภาพเนื้อหา, intent ไม่ชัด, duplicate content, canonical ผิด, noindex, internal link อ่อน หรือ Google เห็นว่าไม่คุ้มต่อการ Index
Robots.txt ผิด
Robots.txt ผิดมักเกิดในช่วง migration, deploy staging, เปลี่ยน plugin, เปลี่ยนโครงสร้าง URL หรือ copy config จากเว็บอื่นมาใช้โดยไม่ตรวจ path จริง ก่อน deploy ควรมี checklist ตรวจ robots เสมอ
Duplicate URL
URL ซ้ำ เช่น ?utm=, ?filter=, trailing slash mismatch, uppercase/lowercase หรือ HTTP/HTTPS ซ้อนกัน สามารถทำให้ Sitemap สกปรกและทำให้ Search Engine เสียเวลา ทีม Developer ควรวาง redirect, canonical และ URL normalization ให้ชัดเจน
Technical SEO สำคัญกับธุรกิจอย่างไร
Technical SEO ไม่ใช่งานหลังบ้านที่มีผลเฉพาะ Developer แต่เป็นรากฐานของรายได้จาก Organic Search หากเว็บไซต์มีบทความดี บริการดี หรือสินค้าดี แต่ Search Engine Crawl และ Index ได้ไม่ถูกต้อง โอกาสทางธุรกิจจะหายไปโดยที่ทีม Marketing อาจไม่เห็นสาเหตุทันที
สำหรับธุรกิจที่ทำ SEO ระยะยาว การเข้าใจว่า Sitemap และ Robots.txt สำคัญอย่างไร ช่วยให้ตัดสินใจเรื่องโครงสร้างเว็บได้ดีขึ้น เช่น จะเปิด landing page ใหม่อย่างไร จะจัดหมวดบริการอย่างไร จะกันหน้าระบบภายในอย่างไร และจะวัดปัญหา Index อย่างไรหลัง deploy
มุมมองแบบ Software House ที่ทำงานกับเว็บไซต์จริงคือ SEO ไม่ควรถูกแก้ปลายทางหลังเว็บเสร็จ แต่ควรถูกออกแบบร่วมกับ architecture ตั้งแต่แรก ทั้ง URL structure, sitemap strategy, robots rules, schema, performance, Core Web Vitals และ content model
แนวทาง Technical SEO สำหรับเว็บไซต์ยุคใหม่
เว็บไซต์ยุคใหม่ไม่ได้มีแค่ HTML คงที่ แต่มี JavaScript rendering, headless CMS, CDN, cache layer, multilingual routing, API, personalization และ dynamic content มากขึ้น Sitemap และ Robots.txt จึงควรถูกออกแบบร่วมกับระบบ ไม่ใช่ปล่อยให้ plugin สร้างตามค่า default โดยไม่มีใคร audit
แนวทางที่แนะนำคือทำ Technical SEO Review ทุกครั้งที่มีการเปลี่ยนโครงสร้างเว็บ เช่น redesign, migration, เปลี่ยน domain, เปลี่ยน CMS, เพิ่มภาษา, เพิ่ม post type, เพิ่ม product filter หรือเปลี่ยน routing เพราะการเปลี่ยนเหล่านี้มีผลต่อ Crawling และ Indexing โดยตรง
แหล่งข้อมูลภายนอกที่ควรใช้เป็น reference ได้แก่ Google Search Central, เอกสาร Build and Submit a Sitemap, เอกสาร Robots.txt ของ Google, คู่มือ Google Search Console และเอกสารของ plugin ที่ใช้งานจริง เช่น Rank Math หรือ Yoast SEO
Checklist ก่อน Submit Sitemap ไป Google
- ตรวจว่า Sitemap เปิดได้และตอบ HTTP 200
- URL ใน Sitemap เป็น canonical URL
- ไม่มี URL noindex อยู่ใน Sitemap
- ไม่มี URL redirect, 404, 410 หรือ 5xx
- ไม่มี staging, localhost หรือ dev domain
- ไม่มี URL ที่ถูก block โดย Robots.txt แบบไม่ตั้งใจ
lastmodสะท้อนการเปลี่ยนเนื้อหาจริง- Robots.txt ระบุ Sitemap URL ถูกต้อง
- ตรวจใน Google Search Console หลัง submit
- ตรวจ Page Indexing Report หลัง Google ประมวลผล
สรุป Sitemap และ Robots.txt สำคัญอย่างไร
Sitemap และ Robots.txt สำคัญอย่างไร สรุปได้ว่า Sitemap ช่วยให้ Search Engine ค้นพบ URL สำคัญของเว็บไซต์ ส่วน Robots.txt ช่วยควบคุมพื้นที่ที่ crawler ควรหรือไม่ควรเข้าอ่าน ทั้งสองไฟล์เป็นรากฐานของ Technical SEO ที่ส่งผลต่อ Crawling, Indexing, Crawl Budget และความสะอาดของโครงสร้างเว็บไซต์
เว็บไซต์ที่ตั้งค่า Sitemap และ Robots.txt ดีจะทำให้ทีม SEO ตรวจปัญหาได้ง่ายขึ้น Developer deploy ได้มั่นใจขึ้น และธุรกิจมีพื้นฐาน Organic Search ที่แข็งแรงขึ้นในระยะยาว แม้สองไฟล์นี้ไม่ใช่ปัจจัยจัดอันดับโดยตรงแบบแยกเดี่ยว แต่เป็นระบบสนับสนุนที่ทำให้เนื้อหาดี ๆ มีโอกาสถูกค้นพบและแข่งขันได้จริง
FAQ
Sitemap คือไฟล์หรือหน้าเว็บที่รวบรวม URL สำคัญของเว็บไซต์ เพื่อช่วยให้ Search Engine ค้นพบและเข้าใจโครงสร้างเว็บไซต์ได้ง่ายขึ้น โดยรูปแบบที่ใช้กับ SEO มากที่สุดคือ XML Sitemap
Robots.txt คือไฟล์ข้อความที่บอก crawler ว่าส่วนใดของเว็บไซต์อนุญาตหรือไม่อนุญาตให้ Crawl ใช้ควบคุม Crawling แต่ไม่ใช่เครื่องมือสั่ง Noindex โดยตรง
Sitemap ไม่ได้จำเป็นในเชิงที่เว็บไม่มีแล้ว Google จะเข้าไม่ได้เสมอไป แต่เป็น best practice สำหรับ SEO โดยเฉพาะเว็บใหม่ เว็บใหญ่ เว็บที่มีหน้าเยอะ หรือเว็บที่ต้องการตรวจ Index ผ่าน Google Search Console อย่างเป็นระบบ
มีผลทางอ้อมต่อ SEO เพราะควบคุมการ Crawl หากตั้งค่าผิดอาจทำให้ Googlebot เข้าไม่ถึงหน้าสำคัญหรือ asset สำคัญ เช่น CSS และ JavaScript ซึ่งกระทบการเข้าใจหน้าเว็บและการ Index ได้
WordPress รุ่นใหม่มี Sitemap พื้นฐานใน core แต่เว็บไซต์ธุรกิจมักใช้ Rank Math หรือ Yoast SEO เพื่อควบคุม Sitemap ได้ละเอียดกว่า เช่น เลือก post type, taxonomy และหน้า noindex ที่ไม่ควรอยู่ใน Sitemap
ระยะเวลาไม่ตายตัว Google อาจอ่าน Sitemap ได้เร็ว แต่การ Crawl และ Index แต่ละ URL ขึ้นกับคุณภาพหน้า ความสำคัญของ URL internal links server response และสัญญาณอื่น ๆ ในระบบ Search
ได้ หากใช้ Disallow กับ user-agent ที่ครอบคลุม Googlebot หรือใช้ User-agent: * Googlebot จะเคารพกฎนั้น แต่ควรใช้อย่างระมัดระวัง เพราะการ block ผิดอาจทำให้หน้าสำคัญไม่ถูก Crawl